Så använder Google användardata för ranking
Publicerad 14 november 2023, senast uppdaterad 2023-11-14

Den pågående rättegången i USA om Googles ställning på sökmotormarknaden har inneburit att flera interna Google-dokument som inte varit tänkt att delas med utomstående har blivit offentliga. Flera av dessa dokument ger större insyn i hur Google fungerar – särskilt gällande hur användarsignaler påverkar sökresultaten.
Varför är det här en så stor grej? Google har i alla år, snällt tolkat, varit väldigt ambivalenta i sin kommunikation kring huruvida användarsignaler såsom klick skulle vara en rankingfaktor. Det vanligaste har varit ganska vaga uttalanden men man har även konfrontativt förnekat att det skulle vara så. Det enda bekräftade undantaget har varit historisk användardata som använts för att förbättra Rankbrain.
Dessa nyligen framkomna dokument, som aldrig varit tänkt att publiceras externt, ger en helt annan bild av hur användardatan faktiskt tycks ha använts genom åren.
Vi har läst igenom materialet som släppts och här går vi igenom det de mest intressanta delarna och våra tankar om vad det innebär.
De tre grundpelarna för ranking
Enligt ett av dessa dokument är användarsignaler faktiskt en av de tre grundpelarna för ranking, jämte innehåll och länkar.
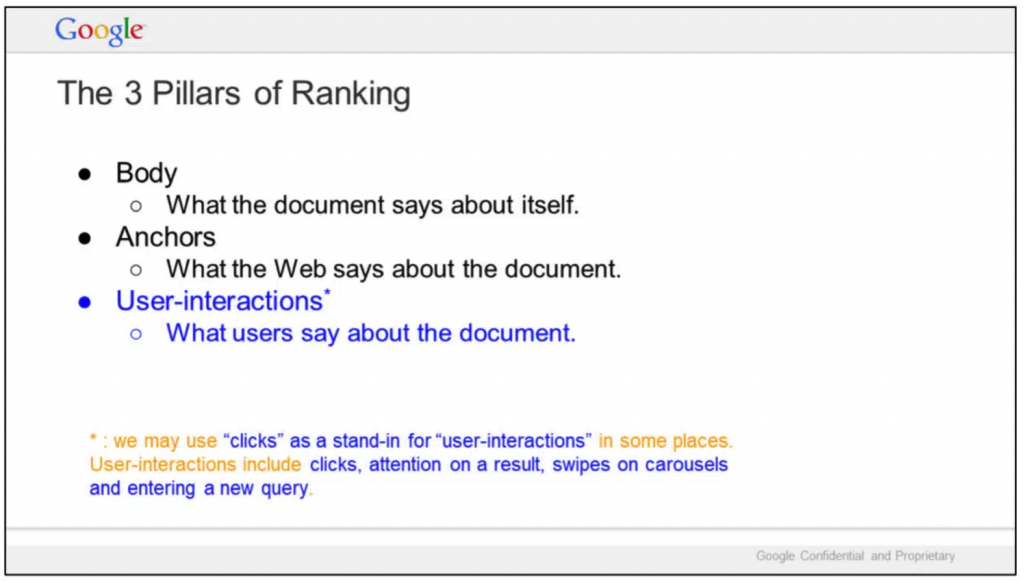
Användarsignalerna som gäller
De interaktioner som Google fokuserar på är vilka resultat i serpen som användaren läser, klick, swipes och hovringar över sökresultat.
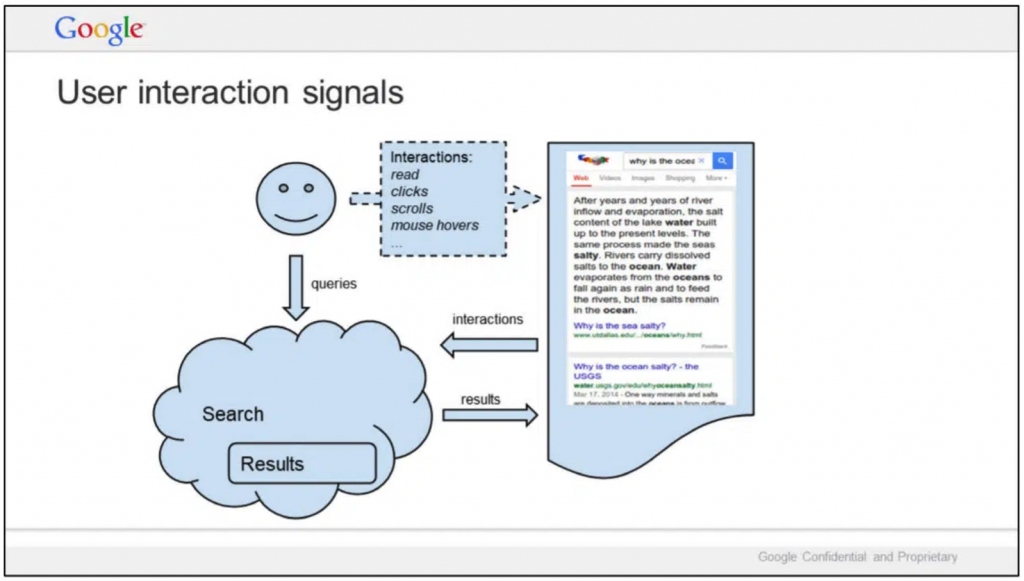
Enligt Googles logik gör varje sökning sökresultaten lite bättre. Varje användare bidrar alltså med lite mer data som iterativt förbättrar användarupplevelsen för de som kommer efter. (Källa: Q4 Search all hands)
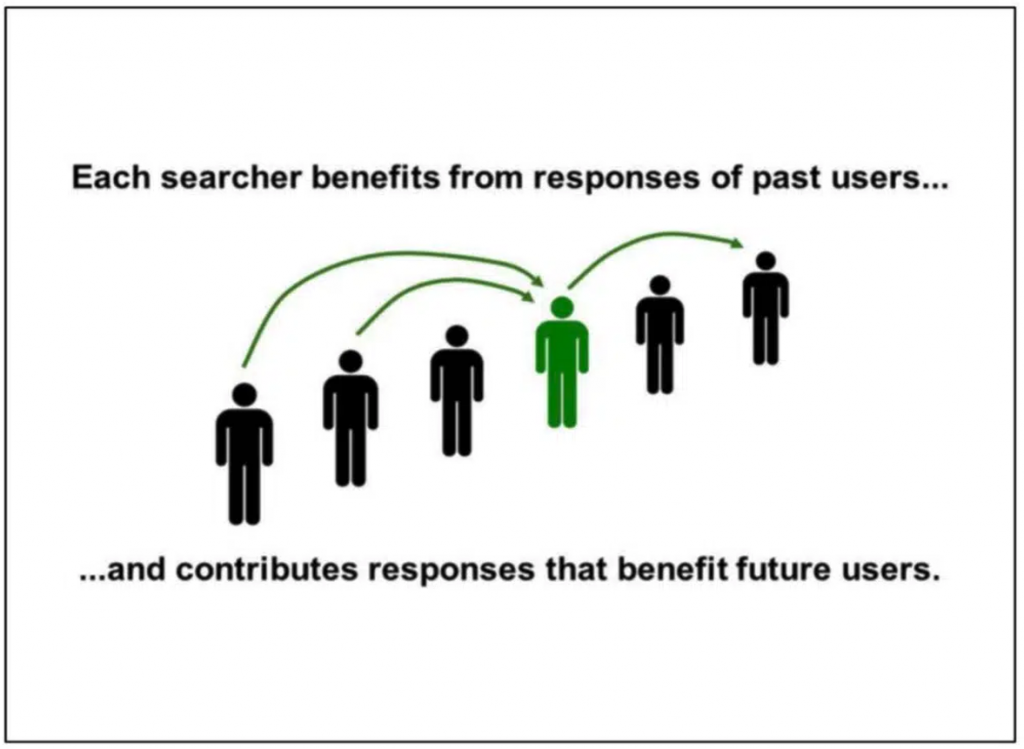
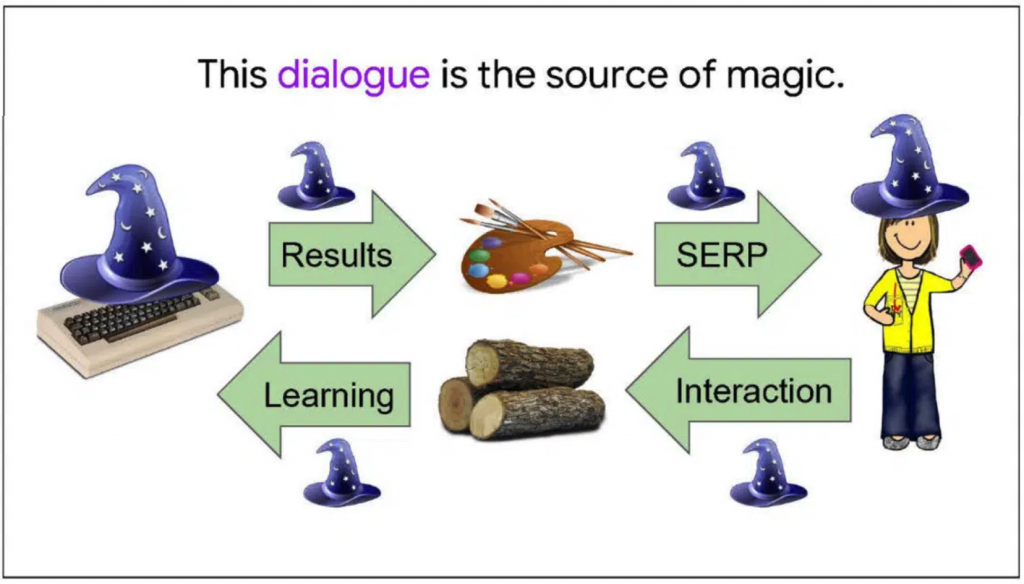
Dialogen är källan till Googles magi
I dokumentet Google is magical får vi mer insyn i hur Google menar att användarsignaler är källan till deras ”magi”.
Att en användare skriver in en sökning, Google värderar den och därefter presenterar ett sökresultat är ett ensidigt sätt att se på hur Google fungerar.
Det är istället dialogen, där Google lär sig av användarens sökningar, som är källan till deras ”magi”.
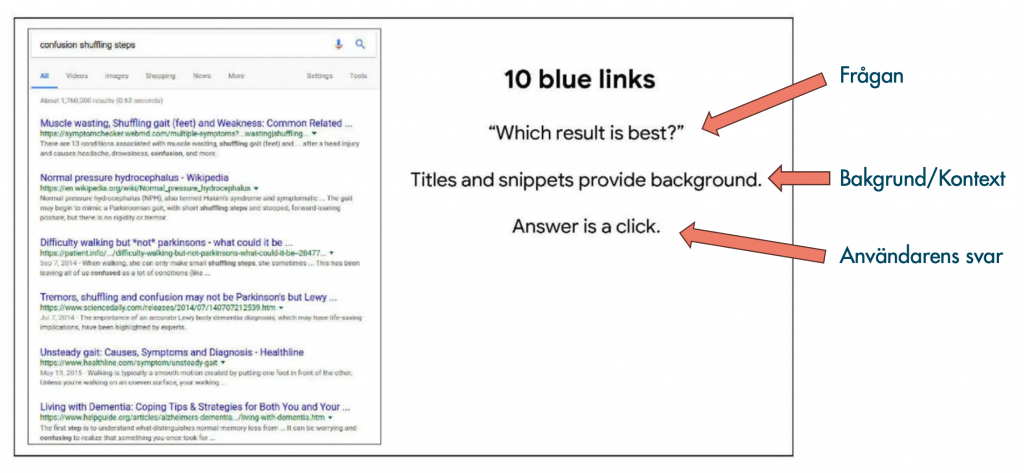
Frågor som Google ställer för att lära sig
Samma dokument går igenom mer i detalj hur Google tänker för att lära sig mer från användarna. Denna process bygger på att implicit ställa frågor till användarna, ge dem lite bakgrundskontext och ett sätt för denne att svara.

Ett helt vanligt sökresultat är ett exempel på där dessa frågor ställs.
Inte bara de modernare systemen
I ett dokument kallat Logging & Ranking framgår att det inte är bara ett rankingsystem som lär sig av så kallade loggar (aggregerade användarsignaler såsom klick, swipes, scrolls, etc). Att lära från loggarna är t.o.m. den centrala mekanismen bakom att ranka sidor.
Google har tidigare sagt att just RankBrain använder sig av historisk användardata men aldrig att de äldre systemen gjort detsamma i, vad det verkar, alla tider.

Fortfarande samma behov av användardata?
Vi vet inte till vilken grad Google använder denna typ av data idag. Majoriteten av dessa dokument har några år på nacken och Googles möjligheter att förstå innehåll utan att behöva förlita sig på användarsignaler till samma grad torde vara ännu större nu i och med utvecklingen inom AI. BERT nämns som ett stort genombrott i Googles möjligheter att förstå innehåll.

Medvetet nedtystat från Googles sida
Googles interna riktlinjer ger tydliga besked om att inte diskutera användandet av klick i sök på ett sätt som gör att denna vetskap kan nå till utomstående.

Realtid eller enbart historisk data för att förbättra algoritmen?
I dokumenten som kommit fram har jag inte lyckats utröna om Google använder den här datan i mer eller mindre realtid – eller om det alltid är historisk data som används för att förbättra algoritmen, såsom de kommunicerat att de använt datan för t.ex. Rankbrain.
Därför kommer dessa uppgifter fram nu
Rättegången i USA handlar om huruvida Googles position på sökmotormarknaden är ett monopol som behöver ses över och agera mot. Om användarsignaler är en så pass central del i vad som gör Google till den främsta sökmotorn på marknaden är det mycket svårt, eller rent av omöjligt, för andra sökmotorer utan tillgång till lika stor mängd användare att kunna konkurrera.
Hur det kan påverka vår vardag som digitala marknadsförare
Vi vet ännu inte vad utgången av rättegången kommer att bli om det skulle visa sig att Google bedöms ha ett otillbörligt monopol. Utöver saftiga bötesbelopp kan det såklart bli fråga om att Google på olika sätt behöver göra det lättare för användare att bruka andra sökmotorer. Sådana avtal som Google slutit med Apple som gör Google till standardsökmotor på Apples enheter torde inte kunna se ut på samma sätt i framtiden vid ett sådant scenario.
En given slutsats av detta givet hur användarsignaler tycks användas är såklart att kända varumärken med hög igenkännbarhet har en ”osynlig” fördel i serpen gentemot andra (mindre kända) varumärken. Ju fler som känner igen ett varumärke, desto fler klick (allt annat lika).
AJ Kohn utvecklar sina tankar om ovanstående i sin mycket läsvärda artikel It’s goog enough som ger en skrämmande och dyster bild av hur sökresultaten utvecklats de senaste åren på grund av orsaker som dessa.
För oss som jobbar med SEO innebär väl dessa nyheter egentligen inte några större förändringar i arbetssätt. Vi behöver fortsatt ha en holistisk syn gällande de varumärken vi jobbar med och inte bara stirra oss blinda på vår kanal. Om något positivt ska komma ur detta är det väl att det blir än viktigare att prata varumärkeskännedom med våra kunder – och enklare att ta upp dialoger om exempelvis Share of Search.
Sammanfattningsvis kan vi konstatera att dessa uppgifter som kommit fram inte kan ses som något annat än sensationella. Google har haft alla chanser genom åren att förklara hur det här ligger till men deras svar har antingen varit antingen otydliga eller förnekande. Jag har själv varit tveksam till att användarsignaler skulle användas på det här sättet eftersom de är så pass brusiga och öppnar upp för manipulation, något Google också är inne på i dokumenten som släppts. Från vad vad som framgår av dokumenten är användarsignaler något oerhört centralt, eller har då åtminstone varit det, genom åren.
Alldeles oavsett är dessa dokument en bra påminnelse alltså om att inte ta något för givet – och att särskilt ta sådant som Google kommunicerar med en rejäl skopa salt.
Länk till alla källor
Search Engine Land gjorde en mycket bra sammanfattning av dessa dokument i den här artikeln. Här är länkar till alla deras källor om du själv vill djupdyka i dokumenten.
- Life of a Click (user-interaction) (May 15, 2017)
- Q4 Search All Hands: Ranking (Dec 8, 2016)
- Ranking for Research (November 16, 2018)
- Google is magical. (October 30, 2017)
- Logging & Ranking (May 8, 2020)
- Ranking Newsletter (August 16, 2014)
- Bullet points for presentation to Sundar (Sept. 17, 2019)